크롤러 개발 중 특정 요소를 불러왔음에도 값들이 인식이 안 되고 아래와 같은 오류 메시지가 표시되는 케이스를 발견했다.
Message: stale element reference: element is not attached to the page document
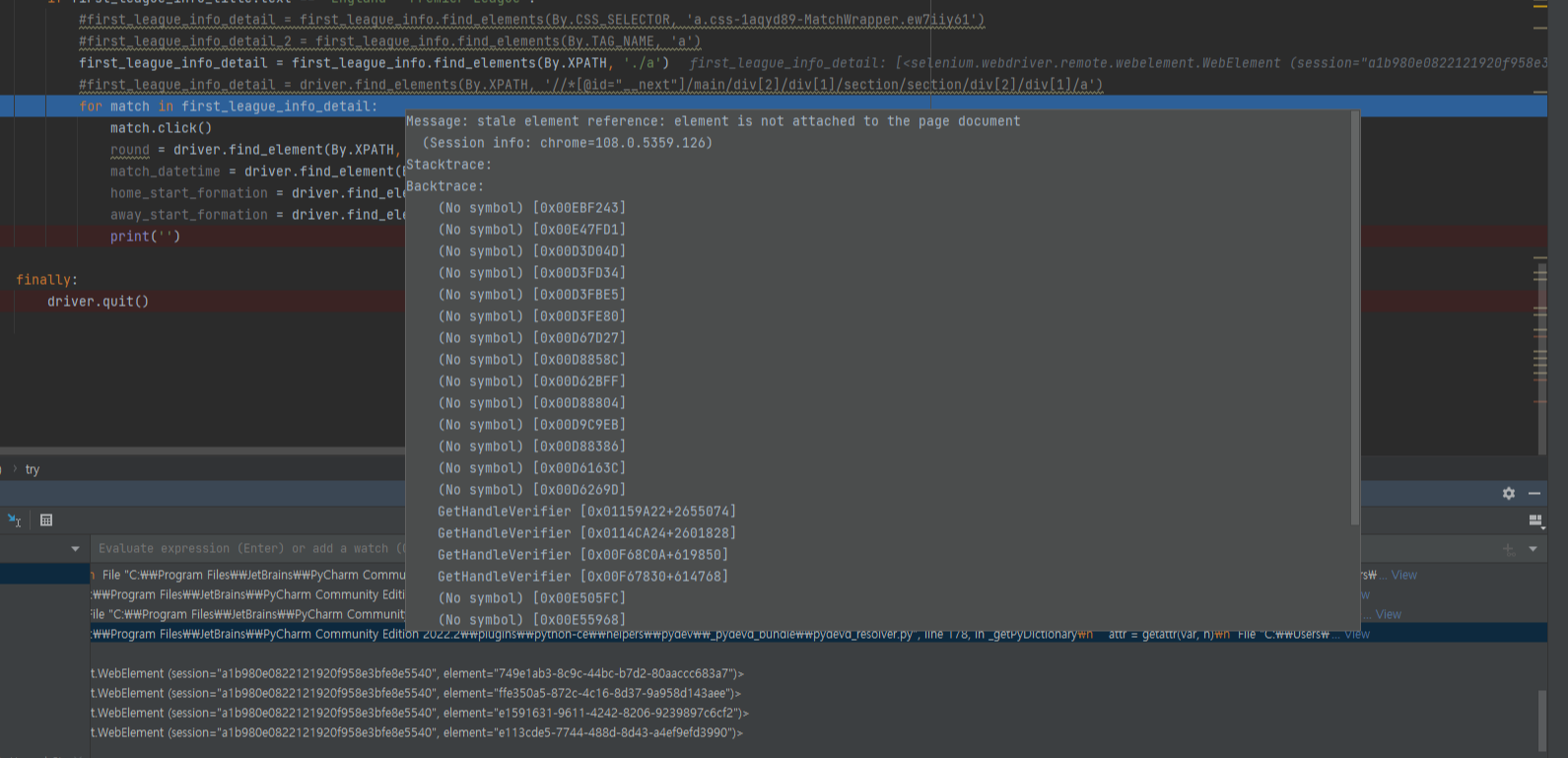
오류 메시지를 살펴보니 stale element를 참조하고 있다고 하는 것으로 보아, WebElement로 가져온 객체 중 저 element ID를 가진 요소가 없는(없어진?) 것으로 보인다.
그런데 이상하다. 현재 화면에서 표시되는 대로라면 리스트가 2개여야 정상인데 사이즈가 6개로 잡히는 게 아닌가.
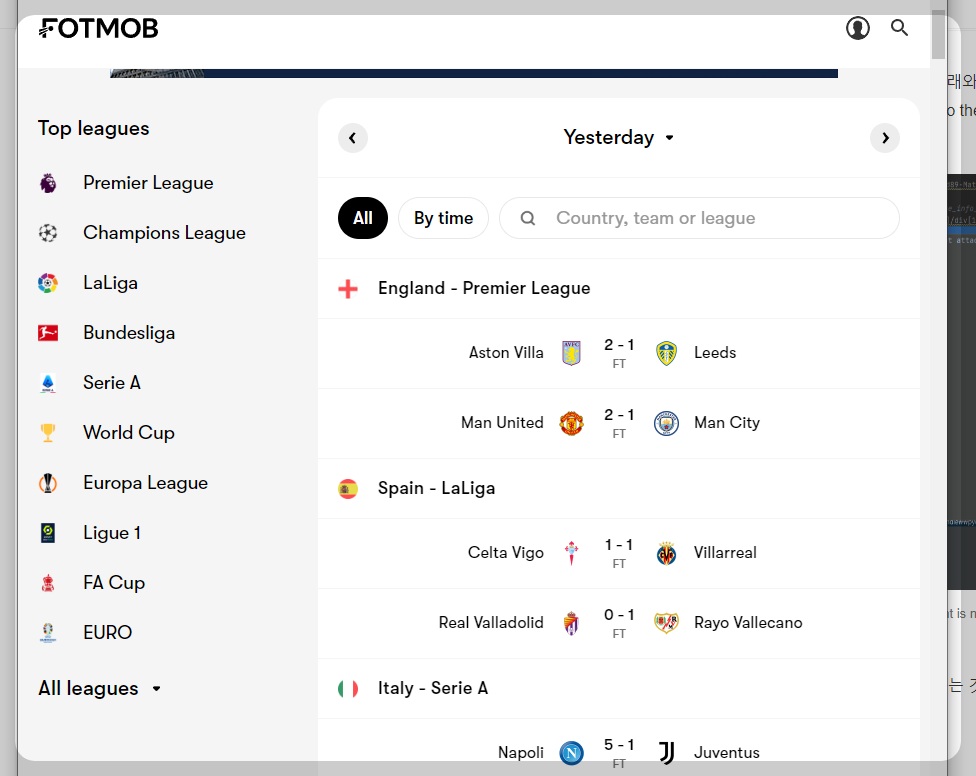
코드가 잘못된 줄 알고 몇 번의 수정과 시행착오 끝에 밝혀낸 범인은 이것이었다.
- 화면에서 처음에는 현지 시간대 기준으로 Yesterday Match Info.를 가져온다.
- 내 코드는 해당 시점에 요소를 읽어들여 List Size가 6이다.
- 내 코드가 객체를 읽은 후, 친절하게도 Fotmob 사이트에서 사용자 시각(GMT+9)을 기준으로 요소를 Refresh 한다.
(이 때 아마 Element ID도 다 변경되어 버리는 것 같다.)
(230120 수정) 자동으로 Refresh가 이루어지는 것이 아니었다. 어떤 이벤트로 인지가 되는지는 모르겠으나 창을 최소화 한 후 다시 활성화하는 시점에 경기 리스트가 6개에서 2개로 Refresh 되더라... - 한국 시간대로 어제 치뤄진 경기는 두 경기이므로, 2번 단계에서 읽은 요소로 Loop를 돌면서 Element를 찾으면 다 사라지고 없겠지? 따라서 기쁘게도 에러가 난다.

따라서 아래와 같이 코드를 수정하였다.
창 최소화와 최대화 사이에 sleep을 걸어주지 않으면 또 제대로 Refresh가 되지 않아서... 부득이하게 추가하였다.
WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="__next"]/main/div[2]/div[1]/section/section/div[2]/div[1]'))
)
driver.minimize_window()
time.sleep(2)
driver.maximize_window()
time.sleep(2)
다음과 같이 정상적으로 객체 인식 & 값 인식이 되는 것을 확인하였다.

Learned - 촌각을 다투는 크롤링이 아니라면 화면 로딩 후 어떤 일이 이루어질지 모르기 때문에 2~3초간의 sleep을 필수로 넣어두어야 할 것 같다. (230120 수정) 사전에 대상 화면을 미리 둘러보고 육안으로 언제, 어떤 부분들이 동적으로 변하는지 잘 살펴봐야겠다.
끝.
'다 배울거야 > Crawling with Selenium' 카테고리의 다른 글
| XPath로 화면의 요소 찾기 (0) | 2023.01.15 |
|---|