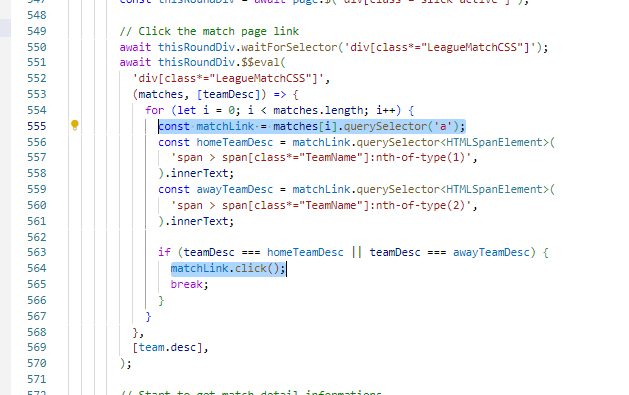
puppeteer 기반의 크롤러 기능 중 loop를 돌며 화면 내의 '다음' 이동 버튼을 클릭하며 데이터를 수집하는 부분을 개발하고 있었다.
클릭 후 자체적으로 setTimeOut을 활용해 만든 delay 함수를 호출시켜 대기 후 루프를 돌게 했는데도 자꾸만 몇개 데이터가 중복으로 들어가서 원인을 찾느라 몇 시간을 썼다.
수집할 데이터 - FOTMOB 사이트의 슈팅 상황
What went wrong?
루프를 도는 함수 내에서 click에 await를 걸어주지 않았다.
수정 후, 원래는 await가 빠져 있었다.
여기서 주의할 점이, puppeteer에서 제공하는 $를 사용해 가져온 객체는 ElementHandle로 반환되고, querySelector를 사용해 가져온 객체는 그냥 Element로 반환된다는 점이다.
다른 로직에서는 eval 함수 내부에서 특정 버튼을 querySelector로 가져왔다.
그렇게 가져온 요소는 Element이므로 click 시에도 Promise를 반환하지 않으므로 그냥 await 없이 동기 호출했다.
이 기억때문에 오류가 난 부분에도 동일하게 await를 걸어주지 않았고, 따라서 click 이후 await 대기한 뒤 후속 작업을 진행해야 하는데 대기 없이 비동기 로직들은 남겨두고 루프가 추가로 돌아버렸고, 그래서 몇번의 중복 루프가 추가적으로 수행 & 중복 데이터가 입력된 것으로 보인다.
해당 matchLink는 Element이므로 click 시에도 Promise를 반환하지 않는다.
Lesson & Learned
따라서puppeteer $ 함수로 가져온 객체를 click시, async 함수 내에서는 반드시 await로 호출해 대기하자.
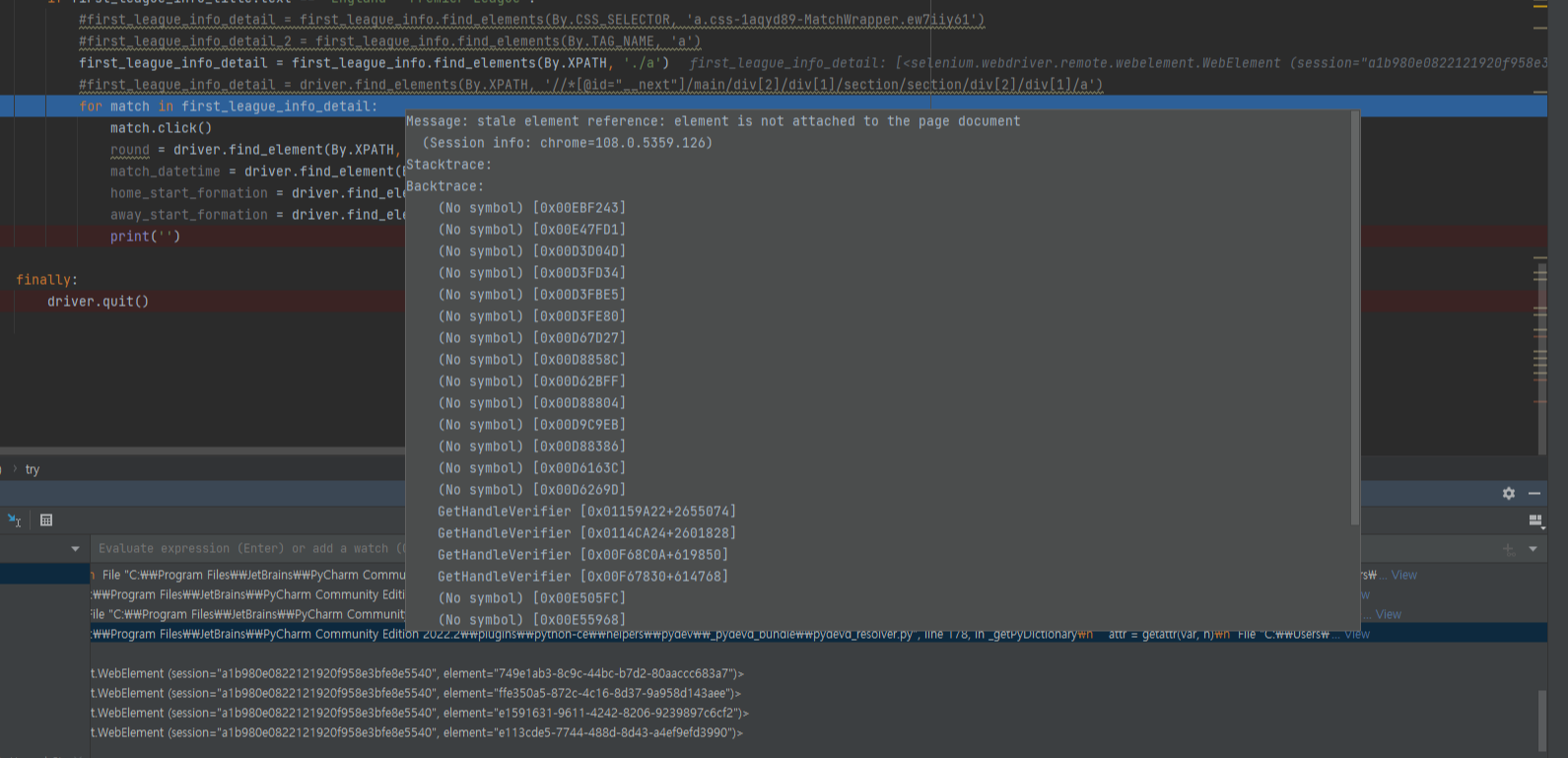
크롤러 개발 중 특정 요소를 불러왔음에도 값들이 인식이 안 되고 아래와 같은 오류 메시지가 표시되는 케이스를 발견했다.
Message: stale element reference: element is not attached to the page document
Message: stale element reference: element is not attached to the page document 오류
오류 메시지를 살펴보니 stale element를 참조하고 있다고 하는 것으로 보아, WebElement로 가져온 객체 중 저 element ID를 가진 요소가 없는(없어진?) 것으로 보인다.
그런데 이상하다. 현재 화면에서 표시되는 대로라면 리스트가 2개여야 정상인데 사이즈가 6개로 잡히는 게 아닌가.
내가 가져오려는 것은 Premier League 하위 2개 a 태그 요소다
코드가 잘못된 줄 알고 몇 번의 수정과 시행착오 끝에 밝혀낸 범인은 이것이었다.
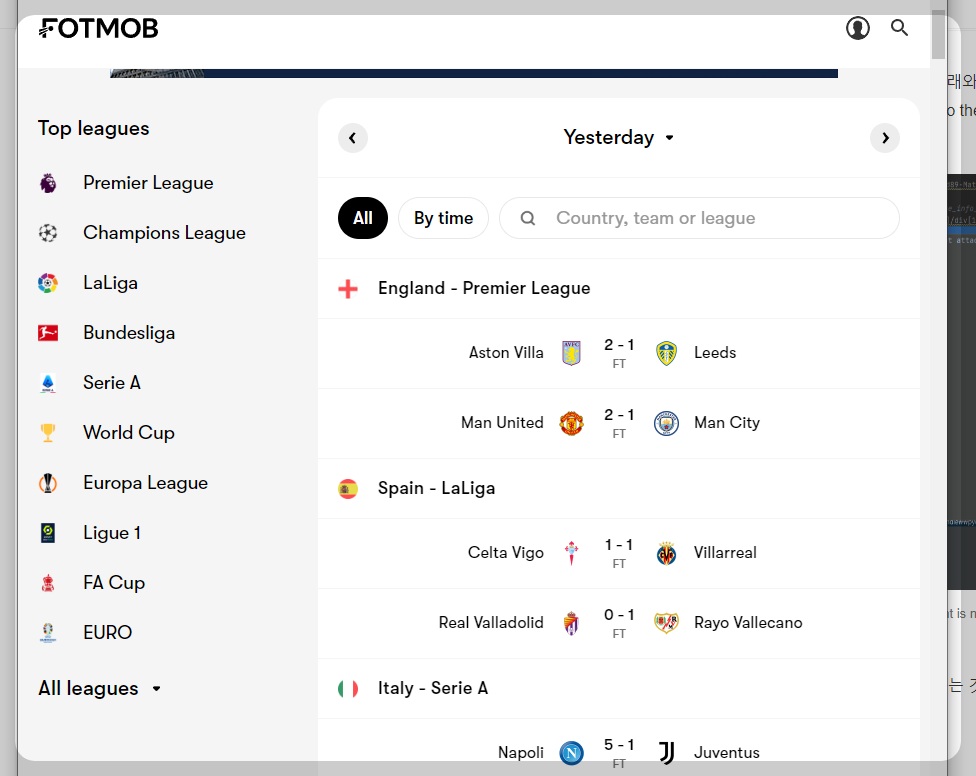
화면에서 처음에는 현지 시간대 기준으로 Yesterday Match Info.를 가져온다.
내 코드는 해당 시점에 요소를 읽어들여 List Size가 6이다.
내 코드가 객체를 읽은 후, 친절하게도 Fotmob 사이트에서 사용자 시각(GMT+9)을 기준으로 요소를 Refresh 한다. (이 때 아마 Element ID도 다 변경되어 버리는 것 같다.) (230120 수정) 자동으로 Refresh가 이루어지는 것이 아니었다. 어떤 이벤트로 인지가 되는지는 모르겠으나 창을 최소화 한 후 다시 활성화하는 시점에 경기 리스트가 6개에서 2개로 Refresh 되더라...
한국 시간대로 어제 치뤄진 경기는 두 경기이므로, 2번 단계에서 읽은 요소로 Loop를 돌면서 Element를 찾으면 다 사라지고 없겠지? 따라서 기쁘게도 에러가 난다.
현지 시간대를 기준으로는 총 6경기가 치뤄졌다
따라서 아래와 같이 코드를 수정하였다.
창 최소화와 최대화 사이에 sleep을 걸어주지 않으면 또 제대로 Refresh가 되지 않아서... 부득이하게 추가하였다.
이렇게 사이트마다 조금씩 특이한 변수들이 존재할 수 있다. 실전에서 부딪혀보지 않으면 알기 힘들겠다.
Learned - 촌각을 다투는 크롤링이 아니라면 화면 로딩 후 어떤 일이 이루어질지 모르기 때문에 2~3초간의 sleep을 필수로 넣어두어야 할 것 같다. (230120 수정) 사전에 대상 화면을 미리 둘러보고 육안으로 언제, 어떤 부분들이 동적으로 변하는지 잘 살펴봐야겠다.